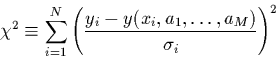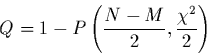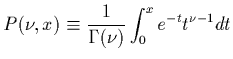Considérons un modèle que l'on souhaite ajuster à des
mesures et qui est défini,pour un jeu de ![]() paramètres
paramètres
![]() par :
par :
| (2.1) |
Moindres carrés et loi de distribution normale:
On cherche donc à établir une relation entre un modèle (i.e. un jeu
de paramètres) ajusté par une méthode des moindres carrés et la
vraisemblance -à définir- de ce modèle. Remarquons tout d'abord
qu'il est dénué de sens de se demander quelle est la probabilité
qu'un modèle soit théoriquement correct -simplement parce qu'il n'existe
pas un «univers de modèles» dont on pourrait extraire le
«vrai». On peut par contre -parce qu'il existe un univers de mesures
possibles dont on extrait des échantillons (en faisant des expériences)- se
poser la question suivante:
«Étant donné un ensemble de paramètres
![]() définissant un modèle, quelle est la probabilité de mesurer ce
modèle (autrement-dit d'obtenir des données qui coïncident avec ce
modèle)?»
définissant un modèle, quelle est la probabilité de mesurer ce
modèle (autrement-dit d'obtenir des données qui coïncident avec ce
modèle)?»
Si l'on ajoute «mesurer exactement» dans la question précédente,
il est clair que cette probabilité sera toujours nulle (parce qu'un point
dans un espace mesurable est toujours de mesure nulle); on ajoutera donc à
notre question : «...de mesurer ce modèle avec une certaine
tolérance ![]() en chaque point de mesure». On définit
ainsi la vraisemblance statistique d'un modèle (ou d'un jeu de
paramètres) vis-à-vis des mesures comme la probabilité d'obtenir ces
mesures lorsque le modèle est choisi (et donc supposé vrai). À
cet égard, et pour tout ce qui va suivre, il ne faut en aucun cas
utiliser cette vraisemblance -qui est une notion purement statistique- comme
preuve de la justesse théorique du modèle.
en chaque point de mesure». On définit
ainsi la vraisemblance statistique d'un modèle (ou d'un jeu de
paramètres) vis-à-vis des mesures comme la probabilité d'obtenir ces
mesures lorsque le modèle est choisi (et donc supposé vrai). À
cet égard, et pour tout ce qui va suivre, il ne faut en aucun cas
utiliser cette vraisemblance -qui est une notion purement statistique- comme
preuve de la justesse théorique du modèle.
On va maintenant calculer cette vraisemblance dans un cas particulier:
supposons donc que chaque mesure ![]() soit entachée d'une erreur
aléatoire, indépendante d'un point de mesure à l'autre, et
distribuée selon une loi normale (gaussienne) relativement au modèle
soit entachée d'une erreur
aléatoire, indépendante d'un point de mesure à l'autre, et
distribuée selon une loi normale (gaussienne) relativement au modèle
![]() supposé vrai. Supposons de plus, pour simplifier, que
l'écart-type de cette loi normale soit le même en tous points de la
mesure. Dans ce cas, la probabilité d'obtenir un ensemble de
supposé vrai. Supposons de plus, pour simplifier, que
l'écart-type de cette loi normale soit le même en tous points de la
mesure. Dans ce cas, la probabilité d'obtenir un ensemble de ![]() mesures
modélisées
mesures
modélisées ![]() (avec une tolérance sur le modèle
(avec une tolérance sur le modèle ![]() ) est le produit des probabilités de l'obtenir en chaque point de mesure,
soit:
) est le produit des probabilités de l'obtenir en chaque point de mesure,
soit:
Erreurs statistiques de mesure et moindres carrés
Attention, l'hypothèse de la distribution normale des erreurs de
mesure par rapport au modèle (ou des écarts au modèle vrai),
invoquée pour considérer l'ajustement aux moindres
carrés comme l'estimation ayant le maximum de vraisemblance, est en fait
assez forte, difficilement vérifiable (puisqu'on ne connaît pas le
«vrai» modèle), et de fait souvent non vérifiée. Il est bien
connu (voir ouvrages de statistique) que lorsqu'on considère une
distribution normale d'écart-type ![]() autour d'une valeur moyenne,
68% des mesures doivent se trouver à
autour d'une valeur moyenne,
68% des mesures doivent se trouver à ![]() , 95% à
, 95% à
![]() , 99.7% à
, 99.7% à ![]() , etc.... Cela nous est habituel
et peut sembler modérément exigeant mais, avec une telle
distribution, on attendra par exemple une mesure en dehors de
, etc.... Cela nous est habituel
et peut sembler modérément exigeant mais, avec une telle
distribution, on attendra par exemple une mesure en dehors de ![]() toutes les
toutes les
![]() mesures, c'est-à-dire jamais!
Or chacun sait que ces points à
mesures, c'est-à-dire jamais!
Or chacun sait que ces points à ![]() existent parfois, même
dans les meilleures conditions d'observation. Ces points de mesure aberrants
( outliers) peuvent rendre un ajustement aux moindres carrés
complètement idiot: leur probabilité est si infime dans la loi normale
que le résultat d'un ajustement aux moindres carrés (donc au maximum de
vraisemblance) sera grandement modifié par la présence d'un seul de ces
points.
existent parfois, même
dans les meilleures conditions d'observation. Ces points de mesure aberrants
( outliers) peuvent rendre un ajustement aux moindres carrés
complètement idiot: leur probabilité est si infime dans la loi normale
que le résultat d'un ajustement aux moindres carrés (donc au maximum de
vraisemblance) sera grandement modifié par la présence d'un seul de ces
points.
Dans certains cas, l'écart à la distribution normale est bien compris ou du moins bien connu: par exemple dans les mesures obtenues par comptage d'événements, les erreurs suivent généralement une distribution de Poisson, qui tend vers une gaussienne lorsque le nombre d'événements devient grand. Mais cette convergence n'est pas uniforme: pour un nombre d'événements donné, les queues des deux distributions diffèrent plus que les c÷urs. Autrement-dit la gaussienne prédit beaucoup moins d'événements marginaux que la distribution de Poisson, si bien que, lorsqu'on ajuste un modèle par la méthode des moindres carrés sur ce type de mesures, les événements marginaux pèsent beaucoup trop sur le résultat. Lorsque la distribution des erreurs n'est pas normale, ou encore lorsqu'on ne peut éviter les points aberrants (traitement en temps réel par exemple), on a recours à des méthodes statistiques particulières, dites méthodes robustes. Nous ne les aborderons pas ici mais il est important de garder en mémoire que les méthodes d'ajustement aux moindres carrés que nous présentons ici, très utiles et très utilisées, supposent toutes que les écarts au modèle soient distribués selon une loi normale.
Remarquons pour finir que la discussion qui précède ne concerne que les erreurs statistiques. Les mesures peuvent aussi être entachées d'erreurs systématiques, i.e. non aléatoires et qui ne disparaissent pas par moyenne statistique. Ces erreurs nécessitent des traitements au cas par cas; elles peuvent provenir simplement de phénomènes physiques non compris (ou non pris en compte dans le modèle, ce qui revient au même), ou de problèmes instrumentaux (parasites, pollution par des instruments voisins, mauvaise calibration, etc...).
Un ajustement prenant en compte les erreurs de mesure en chaque
point: le moindre ![]()
L'ajustement au moindre ![]() ou méthode du chi-carré va consister
à minimiser la quantité suivante:
ou méthode du chi-carré va consister
à minimiser la quantité suivante:
Si les erreurs sont distribuées normalement sur ![]() points de mesure et que
de plus le modèle est linéaire par rapport aux
points de mesure et que
de plus le modèle est linéaire par rapport aux ![]() paramètres
paramètres
![]() , on montre que la probabilité, sur l'espace des
mesures possibles, pour que le chi-carré2.2 d'un modèle supposé vrai
soit supérieur à une valeur donnée
, on montre que la probabilité, sur l'espace des
mesures possibles, pour que le chi-carré2.2 d'un modèle supposé vrai
soit supérieur à une valeur donnée ![]() est
est
Calculée pour le moindre ![]() , cette probabilité
, cette probabilité ![]() donne un
critère de confiance dans l'ajustement: plus
donne un
critère de confiance dans l'ajustement: plus ![]() est grande et plus
l'ajustement obtenu ne peut être considéré comme fortuit (i.e.
purement aléatoire). Si
est grande et plus
l'ajustement obtenu ne peut être considéré comme fortuit (i.e.
purement aléatoire). Si ![]() est très petite, alors l'ajustement pose
problème, soit parce que le modèle est mauvais, soit parce que les
erreurs de mesure sont sous-estimées, soit encore parce qu'il y a trop de
points aberrants par rapport à la distribution normale (mais attention, une
probabilité
est très petite, alors l'ajustement pose
problème, soit parce que le modèle est mauvais, soit parce que les
erreurs de mesure sont sous-estimées, soit encore parce qu'il y a trop de
points aberrants par rapport à la distribution normale (mais attention, une
probabilité ![]() suffisamment grande ne prouve pas pour autant que la
distribution des erreurs soit normale, puisqu'on l'a supposée telle pour
pouvoir calculer cette
suffisamment grande ne prouve pas pour autant que la
distribution des erreurs soit normale, puisqu'on l'a supposée telle pour
pouvoir calculer cette ![]() -et la présence de points aberrants n'est qu'une
façon, parmi une infinité d'autres, d'avoir affaire à une
distribution non normale).
-et la présence de points aberrants n'est qu'une
façon, parmi une infinité d'autres, d'avoir affaire à une
distribution non normale).
A l'inverse, ![]() est quelquefois trop proche de 1, c'est-à-dire que
l'ajustement est en quelque sorte "trop beau pour être vrai". Le modèle
est peut-être génial mais il arrive souvent que dans ce cas
l'expérimentateur ait, par excès de prudence, surestimé les barres
d'erreurs; aussi, avant de considérer un modèle comme parfait (tous les
modèles le sont à une grande incertitude près!), il convient de
revenir sur l'établissement de l'erreur
est quelquefois trop proche de 1, c'est-à-dire que
l'ajustement est en quelque sorte "trop beau pour être vrai". Le modèle
est peut-être génial mais il arrive souvent que dans ce cas
l'expérimentateur ait, par excès de prudence, surestimé les barres
d'erreurs; aussi, avant de considérer un modèle comme parfait (tous les
modèles le sont à une grande incertitude près!), il convient de
revenir sur l'établissement de l'erreur ![]() en chaque point de
mesure (plus rarement, il peut s'agir d'une manipulation frauduleuse des
données). Notons pour finir sur le
en chaque point de
mesure (plus rarement, il peut s'agir d'une manipulation frauduleuse des
données). Notons pour finir sur le ![]() que ses valeurs
utiles (i.e. avec
que ses valeurs
utiles (i.e. avec ![]() demi-entier) sont fréquemment tabulées dans les
ouvrages traitant de statistique (on en donnera quelques valeurs pratiques dans
les sections suivantes). Néanmoins, en l'absence de ces tables ou d'un code
calculant (2.7), donnons un critère2.3 "vite fait" pour apprécier la qualité d'un ajustement
au moindre
demi-entier) sont fréquemment tabulées dans les
ouvrages traitant de statistique (on en donnera quelques valeurs pratiques dans
les sections suivantes). Néanmoins, en l'absence de ces tables ou d'un code
calculant (2.7), donnons un critère2.3 "vite fait" pour apprécier la qualité d'un ajustement
au moindre ![]() : l'ajustement sera acceptable dès lors que
: l'ajustement sera acceptable dès lors que
![]() .
.
Enfin, il arrive que les incertitudes ![]() sur les mesures ne soient
pas connues, ce qui imposera un ajustement aux moindres carrés classique,
mais il est néanmoins utile d'estimer un écart-type
sur les mesures ne soient
pas connues, ce qui imposera un ajustement aux moindres carrés classique,
mais il est néanmoins utile d'estimer un écart-type ![]() sur
ces mesures. Les considérations précédentes relatives au
sur
ces mesures. Les considérations précédentes relatives au ![]() peuvent permettre d'estimer cette valeur: il suffit de rechercher le moindre
peuvent permettre d'estimer cette valeur: il suffit de rechercher le moindre
![]() en assignant une erreur arbitraire constante en chaque point de
mesure et de déduire du modèle obtenu
en assignant une erreur arbitraire constante en chaque point de
mesure et de déduire du modèle obtenu ![]() l'écart-type
l'écart-type ![]() en
calculant la variance du système modèle/mesures à
en
calculant la variance du système modèle/mesures à ![]() degrés de
liberté, soit
degrés de
liberté, soit
![\begin{displaymath}
\sigma^{2}=\frac{1}{N-M}\sum_{i=1}^{N}[y_{i}-y(x_{i})]^{2}
\end{displaymath}](img458.gif) |
(2.8) |
![\begin{displaymath}
\sum_{i=1}^{N}\left[ y_{i}-y(x_{i},a_1,\ldots,a_M)\right]^{2}
\end{displaymath}](img431.gif)
![\begin{displaymath}
P\propto \prod_{i=1}^{N}\left\{
\exp\left[ -\frac{1}{2}\lef...
...ac{y_{i}-y(x_{i})}{\sigma}
\right)^{2}\right]\Delta y \right\}
\end{displaymath}](img438.gif)
![\begin{displaymath}
\left[ \sum_{i=1}^{N}
\frac{[ y_{i}-y(x_{i})]^2}{2\sigma^2}\right]
- N\log\Delta y
\end{displaymath}](img439.gif)