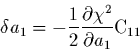Considérons tout d'abord une fonction scalaire ![]() quelconque,
dépendante de plusieurs variables réelles, c'est-à-dire définie
sur un espace affine
quelconque,
dépendante de plusieurs variables réelles, c'est-à-dire définie
sur un espace affine ![]() , où les coordonnées sont exprimées
dans un système d'origine
, où les coordonnées sont exprimées
dans un système d'origine ![]() , et écrivons le début du
développement de Taylor de
, et écrivons le début du
développement de Taylor de ![]() au voisinage de ce point origine:
au voisinage de ce point origine:
Lorsque l'approximation (2.27) est exacte, on dit que ![]() est une
forme quadratique; son gradient s'en déduit immédiatement:
est une
forme quadratique; son gradient s'en déduit immédiatement:
Supposons maintenant que (2.27) soit seulement une (bonne)
approximation de la forme ![]() , on déduit facilement de (2.28) une
formule directe pour converger d'un point initial
, on déduit facilement de (2.28) une
formule directe pour converger d'un point initial ![]() vers un minimum de
vers un minimum de ![]() :
:
Gradient et Hessien du ![]()
Si un modèle à ajuster est donné, pour un jeu de paramètres
![]() choisis,
par
choisis,
par
![]() , la valeur de son
, la valeur de son ![]() par rapport à
par rapport à ![]() mesures
mesures ![]() est une forme (non
forcément quadratique)
définie sur l'espace vectoriel de dimension
est une forme (non
forcément quadratique)
définie sur l'espace vectoriel de dimension ![]() des
paramètres à ajuster par:
des
paramètres à ajuster par:
![\begin{displaymath}
\chi^{2}(\vec{a})=\sum_{i=1}^{N}\left[ \frac{y_{i}-y(x_{i},\vec{a})}
{\sigma_{i}}\right]^{2}
\end{displaymath}](img534.gif) |
(2.31) |
 |
(2.32) |
![\begin{displaymath}
\frac{\partial^{2} \chi^{2}}{\partial a_{k}\partial a_{l}}=2...
... a_{k}}\frac{\partial y(x_{i},\vec{a})}{\partial a_{l}}\right]
\end{displaymath}](img537.gif) |
(2.33) |
Avec ces notations, et en
posant
![]() , autrement dit
, autrement dit
![]() est l'incrémentation à réaliser sur le jeu de paramètres
initial
est l'incrémentation à réaliser sur le jeu de paramètres
initial ![]() dans le schéma de convergence (2.29), la
minimisation d'un
dans le schéma de convergence (2.29), la
minimisation d'un ![]() supposé quadratique revient à résoudre
le système linéaire:
supposé quadratique revient à résoudre
le système linéaire:
Quand changer de méthode pour minimiser le
![]() ? La stratégie de Levenberg-Marquardt
? La stratégie de Levenberg-Marquardt
Levenberg et Marquardt ont proposé une méthode efficace et astucieuse pour passer continûment du schéma d'inversion du hessien à celui des plus fortes pentes. Ce dernier sera utilisé loin du minimum et on tend à lui substituer le schéma d'inversion du hessien au fur et à mesure que l'on approche du minimum. Cette méthode de Levenberg-Marquardt a fait ses preuves et fonctionne remarquablement bien pour des modèles et domaines de la physique fort variés, si bien qu'elle constitue désormais le standard pour résoudre les problèmes d'ajustement aux moindres carrés de modèles non-linéaires.
On peut brièvement décrire la méthode de Levenberg-Marquardt comme
une stratégie de recherche du ![]() minimum utilisant au mieux les
schémas (2.34) et (2.35), et cela grâce à deux
idées déterminantes.
La première idée aboutit à modifier le schéma des plus fortes
pentes (2.35) en remplaçant la constante (le pas) par un vecteur
dont on choisit judicieusement les composantes. On peut interpréter ce
choix comme une "mise à l'échelle", pour chacun des paramètres, du
pas que l'on va effectuer dans la direction du minimum du
minimum utilisant au mieux les
schémas (2.34) et (2.35), et cela grâce à deux
idées déterminantes.
La première idée aboutit à modifier le schéma des plus fortes
pentes (2.35) en remplaçant la constante (le pas) par un vecteur
dont on choisit judicieusement les composantes. On peut interpréter ce
choix comme une "mise à l'échelle", pour chacun des paramètres, du
pas que l'on va effectuer dans la direction du minimum du ![]() .
On réalise ce choix en remarquant que cette constante de proportion entre
une dérivée par rapport à
.
On réalise ce choix en remarquant que cette constante de proportion entre
une dérivée par rapport à ![]() et une différence finie en
et une différence finie en
![]() a naturellement la dimension de
a naturellement la dimension de ![]() . Par ailleurs, on postule
qu'un ordre de grandeur de cette constante peut être donné par une
composante de la matrice de courbure
. Par ailleurs, on postule
qu'un ordre de grandeur de cette constante peut être donné par une
composante de la matrice de courbure ![]() ; or la seule composante de
; or la seule composante de
![]() dépendante de
dépendante de ![]() qui ait la dimension requise est
qui ait la dimension requise est
![]() , et le schéma (2.35) doit donc être modifié
pour s'écrire en composantes:
, et le schéma (2.35) doit donc être modifié
pour s'écrire en composantes:
La deuxième idée consiste alors à poser
![]() , où
, où ![]() est la matrice identité
est la matrice identité ![]() . Les deux schémas (2.34) et (2.36) sont avantageusement
remplacés par l'unique formulation: trouver l'incrémentation
. Les deux schémas (2.34) et (2.36) sont avantageusement
remplacés par l'unique formulation: trouver l'incrémentation
![]() solution du système
solution du système
Incertitudes sur les paramètres ajustés et matrice de covariance
Lorsqu'on a trouvé un minimum acceptable (voir calcul de confiance
section 2.1) du chi-carré pour un jeu de ![]() paramètres
paramètres
![]() , la variation de
, la variation de ![]() autour de ce minimum
autour de ce minimum ![]() pour une variation
pour une variation ![]() des paramètres ajustés est donnée par:
(en appliquant l'équation (2.27) au
des paramètres ajustés est donnée par:
(en appliquant l'équation (2.27) au ![]() et
puisque
et
puisque
![]() )
)
On va s'intéresser en particulier à la variation du ![]() lorsqu'on fait arbitrairement varier un seul
paramètre
lorsqu'on fait arbitrairement varier un seul
paramètre ![]() , les autres paramètres restant fixés à leurs
valeurs ajustées de
, les autres paramètres restant fixés à leurs
valeurs ajustées de ![]() . Notons
. Notons ![]() le moindre
chi-carré à
le moindre
chi-carré à ![]() degrés de liberté obtenu en fixant le
paramètre
degrés de liberté obtenu en fixant le
paramètre ![]() à sa valeur arbitraire et soit
à sa valeur arbitraire et soit ![]() le nouveau jeu
de paramètres qui minimise ce chi-carré. Posons
le nouveau jeu
de paramètres qui minimise ce chi-carré. Posons
![]() et
et
![]() (remarquons qu'aucune des composantes de
(remarquons qu'aucune des composantes de
![]() n'est nulle a
priori).
On montre que ce
n'est nulle a
priori).
On montre que ce
![]() est distribué comme le carré
d'une variable aléatoire à distribution normale2.7. Autrement dit, on aura
formellement
est distribué comme le carré
d'une variable aléatoire à distribution normale2.7. Autrement dit, on aura
formellement
![]() pour
pour
![]() (68.3% des cas),
(68.3% des cas),
![]() pour
pour
![]() (95.4% des cas),
(95.4% des cas),
![]() pour
pour
![]() (99.73% des cas), etc ...
(99.73% des cas), etc ...
On peut par ailleurs relier l'incertitude ![]() sur le paramètre
sur le paramètre
![]() à
à
![]() en remarquant que
en remarquant que
![]() sur toutes ses composantes sauf la première,
et comme, d'après (2.34)
sur toutes ses composantes sauf la première,
et comme, d'après (2.34)
![]() , on aura,
en posant comme en section 2.2.2 la matrice de covariance
, on aura,
en posant comme en section 2.2.2 la matrice de covariance
![]() ,
,
| (2.40) |
| (2.41) |
| (2.42) |